Lab 4: Detecting the Attack

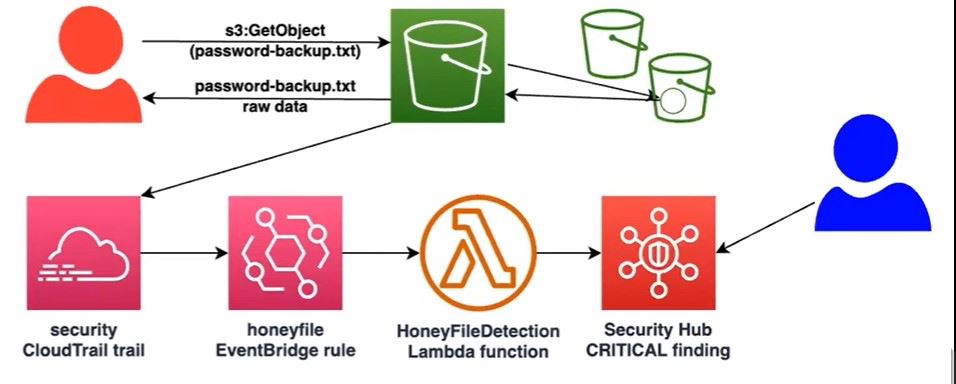
Lab Objective
Discover where the CloudTrail data is being written to within the
cloudlogs-S3 bucketDownload just today's data to your CloudShell session
Analyze the data, looking for all API calls made related to the download of the honey file
Challenge 1: Discover CloudTrail Data Location
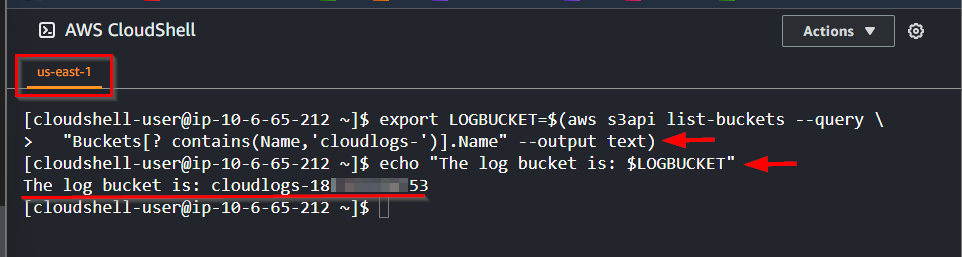
- Run the bash script to export the S3 bucket for log files
export LOGBUCKET=$(aws s3api list-buckets --query \
"Buckets[? contains(Name,'cloudlogs-')].Name" --output text)
echo "The log bucket is: $LOGBUCKET"
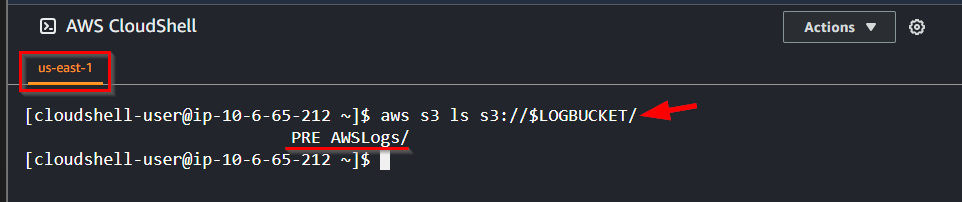
- Now, run the command to view the root of that bucket.
aws s3 ls s3://$LOGBUCKET/
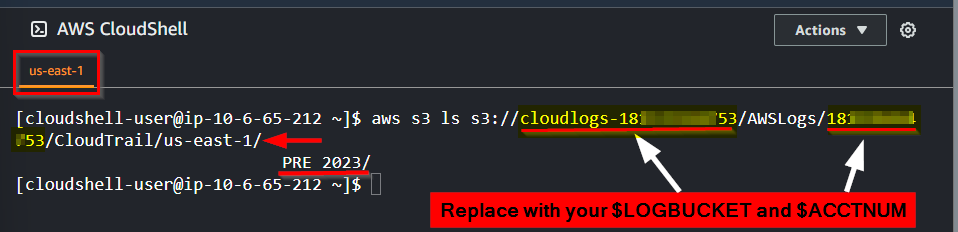
NB: Usually, AWS CloudTrail contains subfolders
- Run the command once to view the list of log files
Replace
$LOGBUCKETwith your bucket name and$ACCTNUMwith your account-ID
aws s3 ls s3://$LOGBUCKET/AWSLogs/$ACCTNUM/CloudTrail/us-east-1/
DATE=$(date +"%Y/%m/%d")
aws s3 ls s3://$LOGBUCKET/AWSLogs/$ACCTNUM/CloudTrail/us-east-1/$DATE/
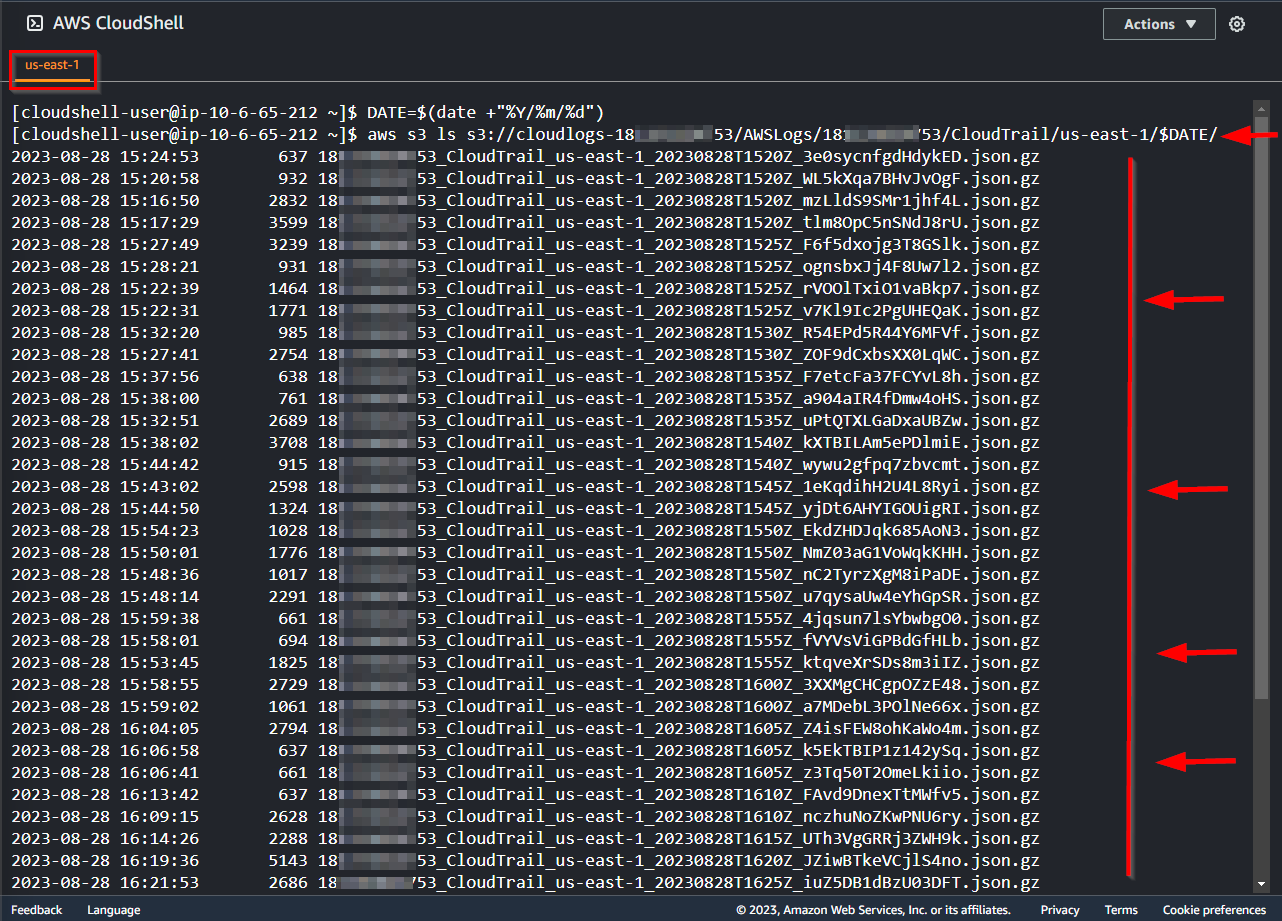
From the Above logs, every 5 minutes or so, one or more GZIP-compressed JSON files are being created. This is the data we are interested in to discover our attacker's actions.
Challenge 2: Download Today's Events
Now that you have the location of the CloudTrail data, download just today's data to your CloudShell session in a folder called cloudtrail-logs in your home directory.
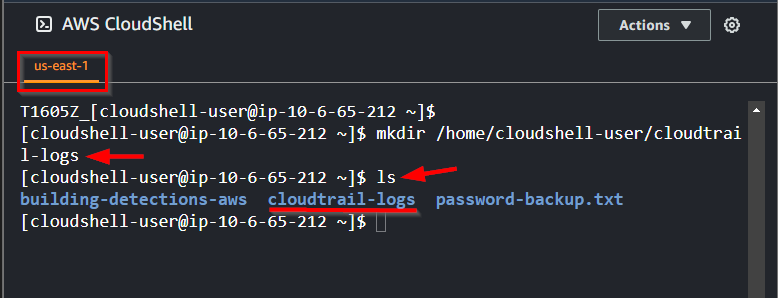
- Create a folder or directory from your CloudShell to store the log files using the command.
mkdir /home/cloudshell-user/cloudtrail-logs
- Next, use the
aws s3 cpcommand to download all of today's CloudTrail data.
Replace
$LOGBUCKETwith your bucket name and$ACCTNUMwith your account-ID
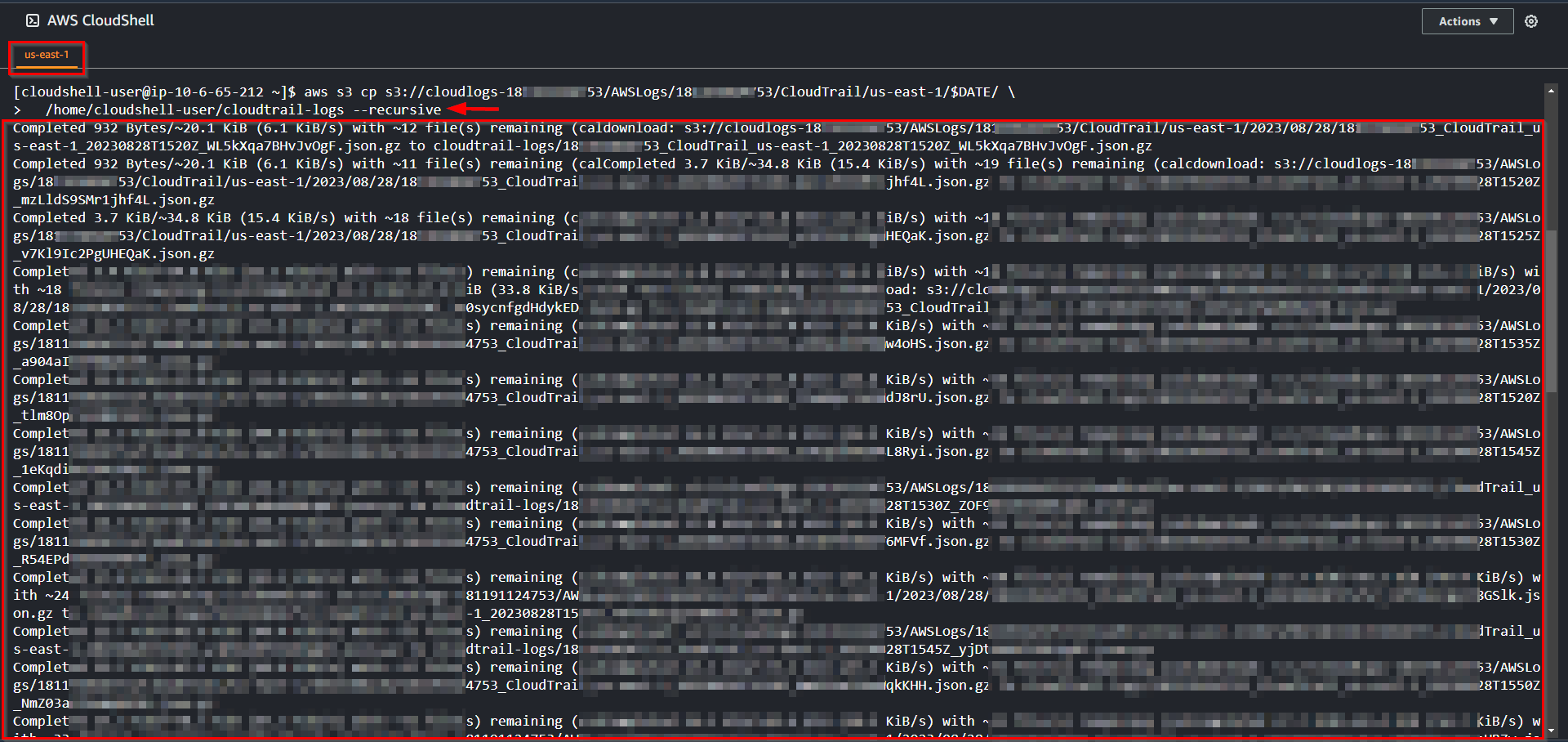
aws s3 cp s3://$LOGBUCKET/AWSLogs/$ACCTNUM/CloudTrail/us-east-1/$DATE/ \
/home/cloudshell-user/cloudtrail-logs --recursive
aws s3 cp s3://cloudlogs-18********53/AWSLogs/18********53/CloudTrail/us-east-1/$DATE/ \
/home/cloudshell-user/cloudtrail-logs --recursive
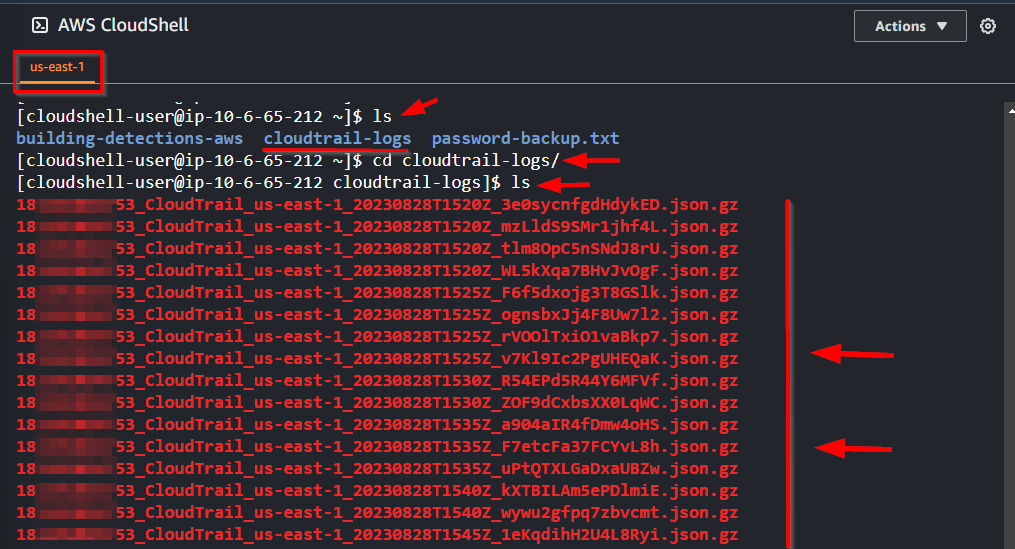
- Check the directory
cd /home/cloudshell-user/cloudtrail-logsto ensure that the logs were properly downloaded.
Challenge 3: Detect Honey File Usage
Use
[zcat](https://www.tecmint.com/linux-zcat-command-examples/)to both expand and view compressed files without uncompressing the files.zcat /home/cloudshell-user/cloudtrail-logs/*.json.gz
WAY TOO MUCH DATA, and not in a readable format

- Utilize the
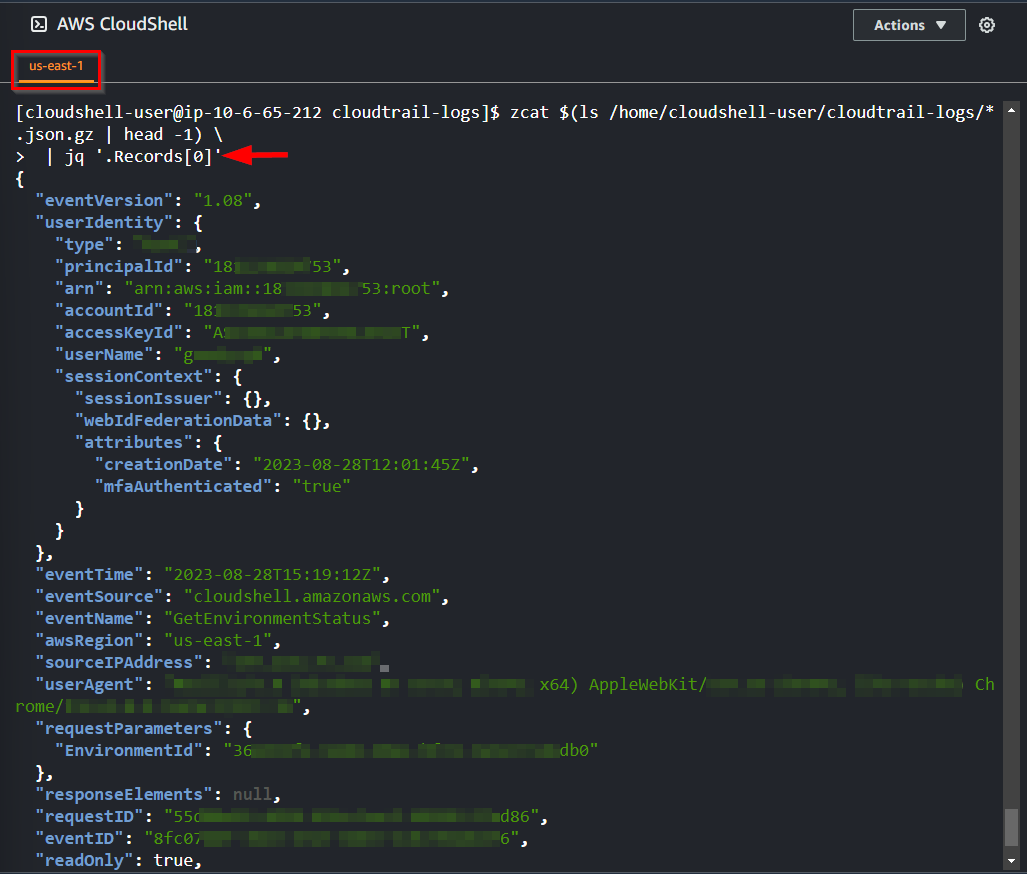
'jq'command to present the data in a more readable format and to preview the log data's structure by viewing only the first record of the initial file.
#NB the .Records[0] means it should open the first log file in JSON format
zcat $(ls /home/cloudshell-user/cloudtrail-logs/*.json.gz | head -1) \
| jq '.Records[0]'
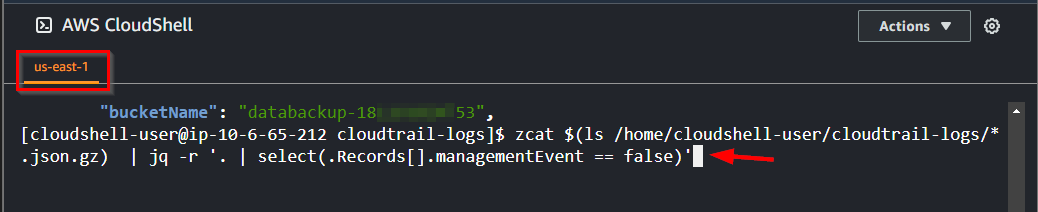
- Since the JSON data event mentioned above might lack comprehensive management events, utilize the following command to search within the log files for occurrences where
managementEventis set tofalse
NB: From the code, the
.Recordisn’t set to any particular file
zcat $(ls /home/cloudshell-user/cloudtrail-logs/*.json.gz) \
| jq -r '. | select(.Records[].managementEvent == false)'
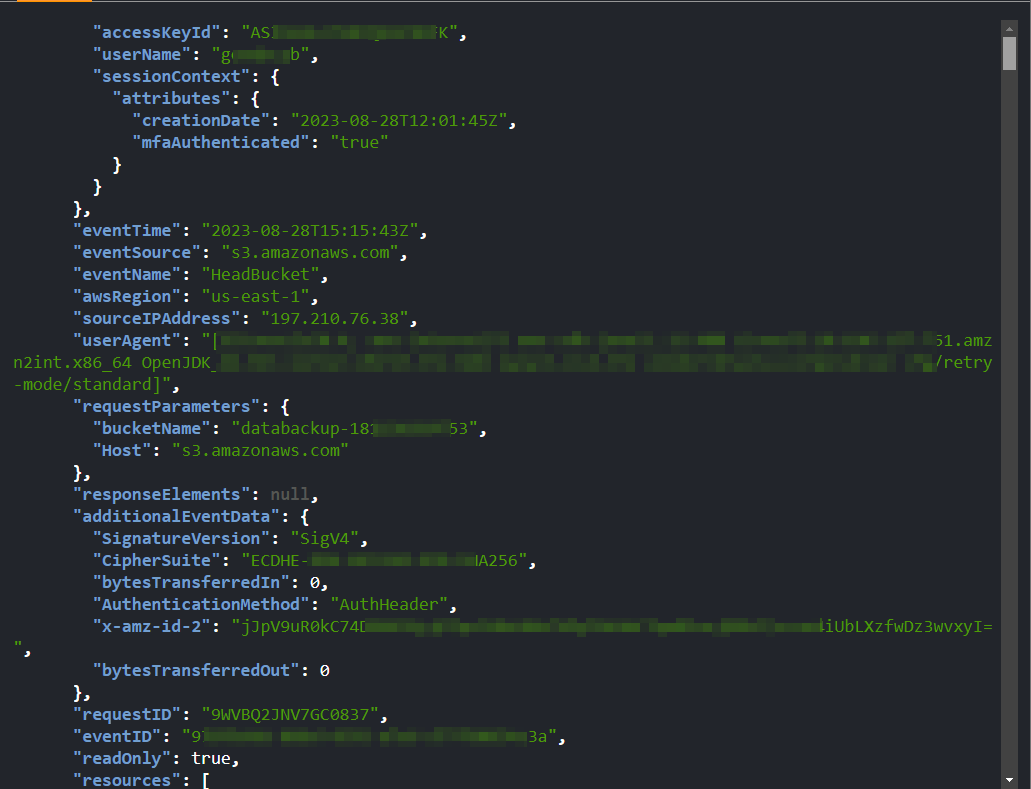
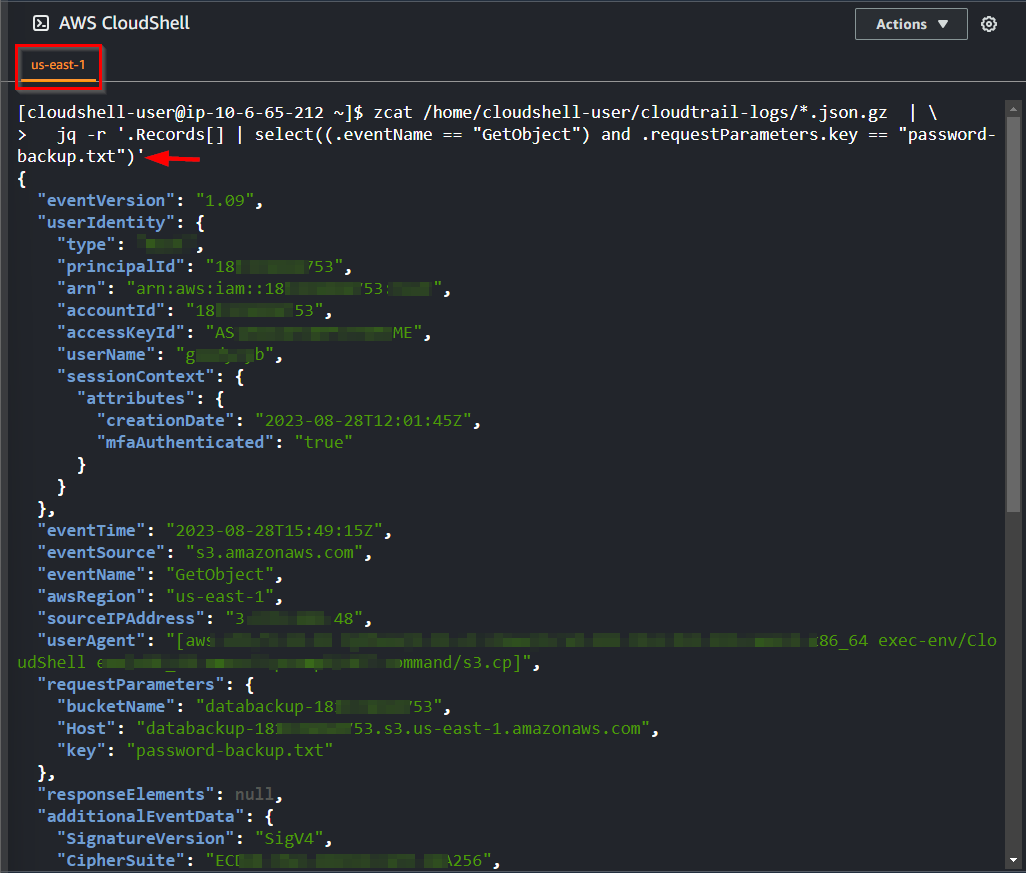
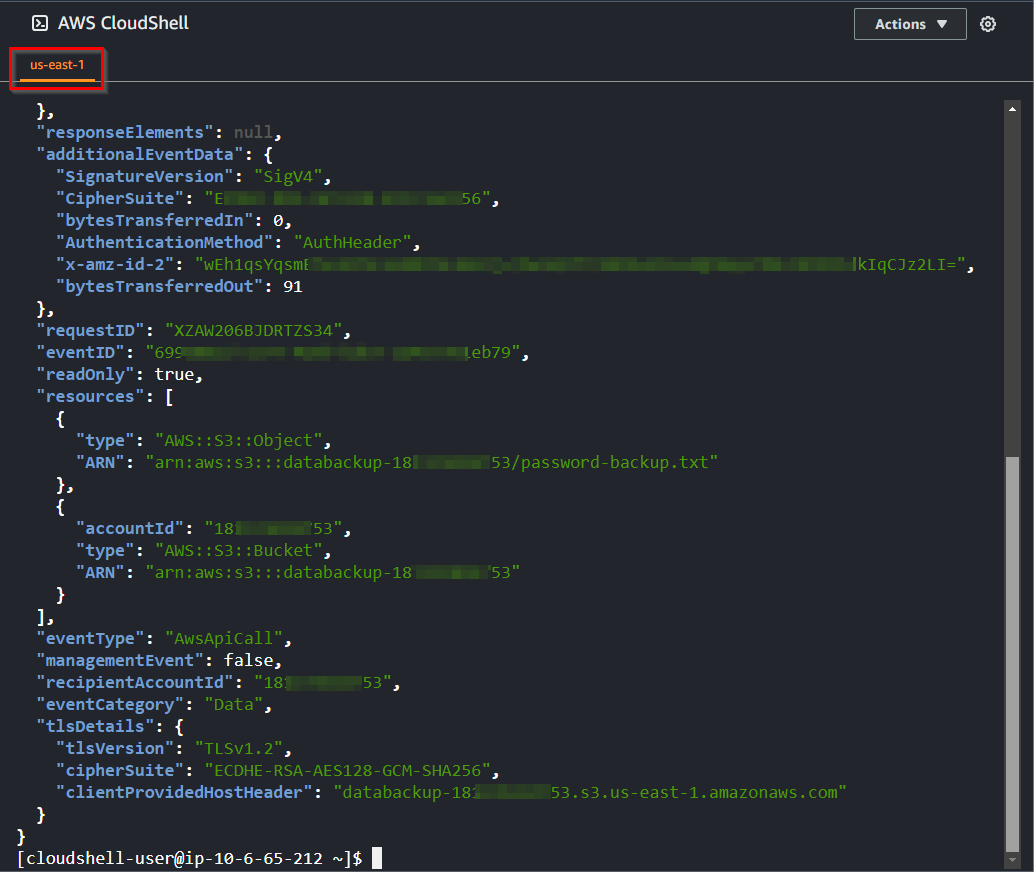
- After reviewing the output of the command above, it remains challenging to pinpoint the honey file's access. Execute the following command to filter the EventName and extract the particular honey file object.
zcat /home/cloudshell-user/cloudtrail-logs/*.json.gz | \
jq -r '.Records[] | select((.eventName == "GetObject") and .requestParameters.key == "password-backup.txt")'
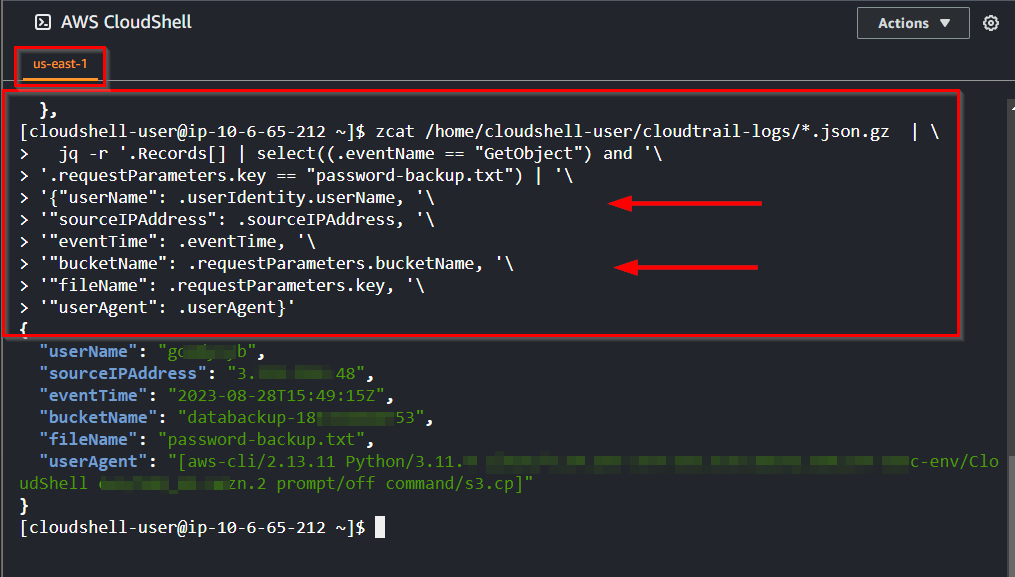
- Run the command to get the exact details of the threat actor or attacker that downloaded or accessed the honey file.
zcat /home/cloudshell-user/cloudtrail-logs/*.json.gz | \
jq -r '.Records[] | select((.eventName == "GetObject") and '\
'.requestParameters.key == "password-backup.txt") | '\
'{"userName": .userIdentity.userName, '\
'"sourceIPAddress": .sourceIPAddress, '\
'"eventTime": .eventTime, '\
'"bucketName": .requestParameters.bucketName, '\
'"fileName": .requestParameters.key, '\
'"userAgent": .userAgent}'
Summary
In this exercise, you experienced a walkthrough of tracking ATT&CK technique T1530 (Data from Cloud Storage) by employing a honey file and analyzing CloudTrail data events in various ways. This process demanded significant manual work. However, the upcoming exercise will focus on automating this discovery process by leveraging specific cloud services.


